


Principais Algoritmos Utilizados em Inteligência Artificial
1. INTRODUÇÃO
Conforme apresentado em postagens anteriores [1],[2] a Inteligência Artificial (IA) é uma área da ciência da computação que desenvolve sistemas capazes de executar tarefas normalmente realizadas por seres inteligentes.
A IA tem sido utilizada nas mais diversas áreas do conhecimento humano, para raciocinar, identificar, classificar, descobrir significado, generalizar, aprender por experiência, tomar decisão, controlar e realizar predições ou prognósticos [1].
2. PRINCIPAIS ALGORITMOS DE IA
Diferentes técnicas matemáticas, estatísticas e computacionais são utilizadas para o desenvolvimento de soluções de IA, conforme a Figura 1. Um verdadeiro arsenal, ou “cinto de utilidades”, de diferentes recursos estão à disposição do pesquisador em IA. Esses algoritmos podem ser utilizados de forma isolada ou combinados, em soluções híbridas, para uma melhor performance.
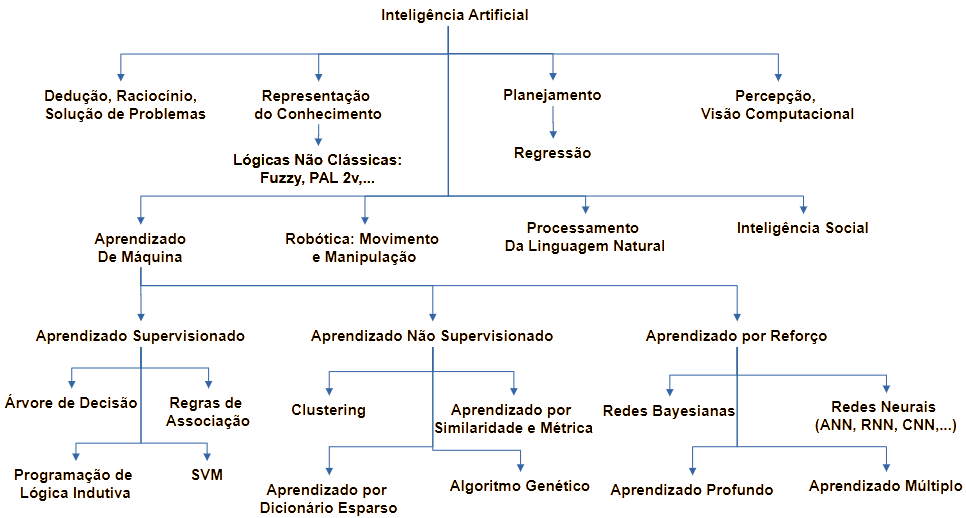
Figura 1 – Algoritmos de IA e ML
Fonte: O Autor (2024)
A seguir são relacionados os principais algoritmos utilizados em IA [3],[4]. Para saber mais, explore as referências indicadas em cada um dos algoritmos.
2.1. Regressão Linear (Linear Regression – LR): Um dos mais conhecidos algoritmos de estatística e muito utilizado no aprendizado de máquinas (machine learning – ML). A LR cria um modelo para a compreensão da relação entre variáveis numéricas de entrada e saída. Isso permite que a LR seja utilizada para prever resultados com base em dados anteriores [5].
2.2. Regressão Logística (Logistic Regression – LR): É um modelo estatístico utilizado que analisa a relação entre 2 fatores de dados. A regressão logística é um algoritmo de ML supervisionado, usado para tarefas de classificação, cujo objetivo é prever a probabilidade de uma instância pertencer ou não a uma determinada classe. É o método estatístico preferido para problemas de classificação binária (problemas com dois valores de classe).[6].
2.3. Aumento Gradual (Gradient Boosting – GB): É uma técnica em melhora predições através de erros passados em passos pequenos. O GB é uma das técnicas mais poderosas para a construção de modelos preditivos [7].
2.4. Bayes Ingênuos (Naive Bayes – NB): É um algoritmo simples porém poderoso para modelagem preditiva. O Teorema de Bayes fornece uma maneira de calcular a probabilidade de uma hipótese dado o conhecimento prévio [8].
2.5. Redes Bayesianas (Bayesian Networks – BN): Também fundamentado no Teorema de Bayes, utiliza probabilidade para realizar predição considerando diferentes fatores. as Redes Bayesianas fornecem uma ferramenta útil para visualizar o modelo probabilístico para um domínio, revisar todas as relações entre as variáveis aleatórias, e razão sobre probabilidades causais para cenários dadas as evidências disponíveis [9].
2.6. Modelo de Markov (Markov Model – MM): São uma classe de Modelos Gráficos Probabilísticos (probabilistic graph models – PGM) que representam processos dinâmicos, ou seja, um processo que não é estático, mas sim que muda com o tempo. Em particular, preocupa-se mais sobre como o estado (state) de um processo muda com o tempo [8]. Em conjunto com a amostragem de Monte Carlo, a cadeia de Markov fornece uma classe de algoritmos para amostragem aleatória sistemática a partir de distribuições de probabilidade de alta dimensão. Ao contrário dos métodos de amostragem de Monte Carlo que são capazes de extrair amostras independentes da distribuição, os métodos de Monte Carlo da Cadeia de Markov coletam amostras onde a próxima amostra depende da amostra existente, chamada de Cadeia de Markov. Isso permite que os algoritmos se restrinjam na quantidade que está sendo aproximada da distribuição, mesmo com um grande número de variáveis aleatórias [10].
2.7. Árvores de Decisão (Decision Tree – DT): é um algoritmo útil de aprendizado de máquina usado para tarefas de regressão e classificação. O nome “Árvore de Decisão” vem do fato de que o algoritmo continua dividindo o conjunto de dados em porções cada vez menores até que os dados sejam divididos em instâncias únicas, que são classificadas, ao tomar decisões do tipo sim ou não em cada instância. Ao visualizar a estrutura dos resultados do algoritmo, a maneira como as categorias são divididas se parecerem com uma árvore e muitas folhas [12],[13].
2.8. Raciocínio por Inferência (Reasoning by Inferences): Lógicas não clássicas como lógica difusa (Fuzzy) [14], paraconsistente e suas variações como a lógica paraconsistente anotada de 2 valores (PAL2v) [15],[16],[17],[18], permitem a construção de algoritmos para tomada de decisão quando informações não estão claramente definidas. Algoritmos PAL2v de referência estão disponíveis em https://sites.google.com/view/prof-arnaldo/pal2v-key-points?authuser=0.
2.9. Redes Neurais Artificiais (Artificial Neural Networks – ANN): redes de neurônios artificiais baseados no cérebro biológico, que aprende por exemplos [1]. Cada neurônio é bloco elementar da rede neural, formado por um conjunto de entradas e saídas que funcionam como sinapses da ANN [5],[6],[7]. O sinal que atravessa uma sinapse pode ter um peso (reforço) maior ou menor ao entrar em um neurônio, dependendo do aprendizado da rede neural. As entradas de cada neurônio são combinadas e aplicadas a uma função de ativação, que processará e apresentará o resultado em sua saída [2],[3]. As ANNs já foram abordadas em postagem anterior [1].
2.10. Redes Neurais Recorrentes (Recurrent Neural Networks – RNN): tipo de rede neural, cuja arquitetura possui realimentações internas, funcionando como efeito memória, permitindo que a RNN entenda sequências como texto e séries temporais de dados [1]. As RNAs podem assim, serem utilizadas na predição e controle de sistemas [6],[7]. Uma evolução das RNAs são as redes de Memória de Termo Curto Longo (long short term memory – LSTM) e Unidades de Portas Recorrentes (gated recurrent units – GRU). As redes LSTM e GRU já foram abordadas em postagem anterior [1].
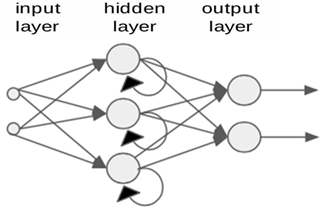
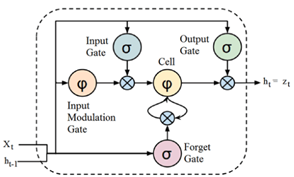
Figura 2 – Conceito de RNN (a) e Unidade LSTM (b).
Fonte: Adaptado de [1].
2.11. Redes Neurais Convolucionais (Convolutional Neural Networks – CNN): são redes neurais especializadas, que permitem computadores ver e entender imagens [1],[2],[3],[19]. Neste tipo de ANN, técnicas de convolução são aplicadas na matriz de dados (como a matriz de pixels de uma imagem), antes da entrada na ANN, de modo a destacar ou realçar determinadas características como objeto, cores, contraste, contornos, etc. São muito utilizadas na identificação e classificação de padrões de imagens. Um exemplo de arquitetura pode ser visto na Figura 3.
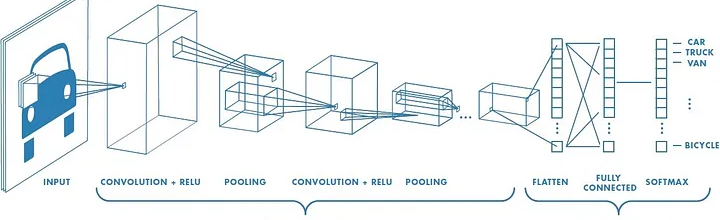
Fonte: Adaptado de [20].
2.12. Conjunto de Significados K (K-Means Clustering): algoritmo que agrupa itens semelhantes, sem uma definição prévia. É frequentemente usado como uma técnica de análise de dados para descobrir padrões interessantes em dados, como grupos de clientes com base em seu comportamento [21].
2.13. Análise de Componentes Principais (Principal Component Analysis – PCA): A PCA é uma técnica de aprendizado de máquina não supervisionada que empacota dados importantes em um pequeno espaço. É usada principalmente na análise de componentes principais seja a redução da dimensionalidade. Além de usar o PCA como técnica de preparação de dados, também pode-se utilizá-la para ajudar a visualizar dados. Com os dados visualizados, é mais fácil obter algumas ideias e decidir sobre a próxima etapa em modelos de aprendizado de máquina [22].
2.14. Auto-Codificadores (AutoEncoders): Autoencoders (AE) são redes neurais que visam copiar suas entradas para suas saídas. Especificamente, projetaremos uma arquitetura de rede neural de modo a impor um gargalo na rede que força uma representação de conhecimento compactada da entrada original. Se houver algum tipo de estrutura nos dados (ou seja, correlações entre os recursos de entrada), essa estrutura poderá ser aprendida e consequentemente aproveitada ao forçar a entrada através do gargalo da rede. Assim, o AE comprime e depois reconstrói imagens [23].
2.15. Aprendizagem de Reforço (Reinforcement Learning – RL): aprende com recompensas, ou seja, o computador é recompensado por boas ações e erros são corrigidos [24].
2.16. Aprendizado Q (Q-Learning): encontra o melhor caminho em um labirinto, através da exploração e recompensa. O processo de Q-Learning cria uma matriz (tabela) exata para o agente a qual ele “consulta” para maximizar sua recompensa a longo prazo durante seu aprendizado [25].
2.17. Vizinhos Mais Próximos (K Nearest Neighbors – K-NN): encontra vizinhos mais próximos para fazer predições. As previsões são feitas para uma nova instância (x) pesquisando todo o conjunto de treinamento para as instâncias mais semelhantes (os vizinhos) e resumindo a variável de saída para essas instâncias K. Para regressão, essa pode ser a variável de saída média, na classificação, esse pode ser o valor do modo (ou mais comum) [26].
2.18. Florestas Aleatórias (Randon Forest – RF): combina várias respostas para precisão. O RF utiliza um conjunto de Árvores de Decisão para realizar tarefas de classificação ou regressão. O método da Floresta Aleatória, que se dá pela combinação de outros métodos são denominados como ensemble. O conceito fundamental das Florestas Aleatórias é a sabedoria das multidões: um número grande de modelos não correlacionados, no caso as árvores, operando em conjunto performarão melhor do que cada modelo individual [27].
2.19. Máquina Vetorial de Suporte (Support Vector Machine – SVM): Máquinas de vetores de suporte são um conjunto de métodos de aprendizado supervisionado utilizados para classificação, regressão, e detecção de outliers. Todas essas são tarefas comuns em aprendizado de máquina. Um classificador SVM linear simples funciona criando uma linha reta entre duas classes. Isso significa que todos os pontos de dados de um lado da linha representarão uma categoria, e os pontos de dados do outro lado da linha serão colocados em uma categoria diferente. Isso significa que pode haver um número infinito de linhas para escolher [28].
2.20. Algoritmos Genéticos (Genetic Algorithm – GA): O GA é um metaheurístico inspirado no processo de seleção natural que pertence à maior classe de algoritmos evolutivos (EA). Ele evolui na solução ao combinar as melhores opções através do tempo. Os algoritmos genéticos são comumente usados para gerar soluções de alta qualidade para otimização e problemas de pesquisa, confiando em operadores biologicamente inspirados, como mutação, crossover e seleção. Exemplos de aplicações de GA incluem otimizar as árvores de decisão para melhor desempenho, resolver quebra-cabeças otimização de hiper parâmetro, inferência causal, etc. [29].
2.21. Redes Transformadoras (Transformer Networks – TN): As redes Transformer vem ganhando bastante interesse entre pesquisadores nos últimos anos. O Transformer é um modelo de aprendizado profundo introduzido em 2017 que utiliza o mecanismo de atenção, pesando a influência de diferentes partes dos dados de entrada. O Transformer é uma arquitetura que visa resolver tarefas sequência-à-sequência enquanto lida com dependências de longo alcance com facilidade. Ele se baseia inteiramente na auto atenção (Self-Attention) para computar as representações de sua entrada e saída sem usar RNNs (Redes Neurais Recorrentes) alinhadas em sequência ou convolução. São algoritmos complexos e que exigem grande capacidade computacional. As redes Transformer tem sido utilizadas no processamento de linguagem natural e análise de séries temporais [30]. A Figura 4 apresenta um modelo da arquitetura de Rede Transformer [31].
Figura 4 – Modelo de Arquitetura do Algoritmo de Rede Transformer
Fonte: Adaptado de [31]
3. CONCLUSÃO
Esta postagem procurou agrupar e relacionar as principais classes de algoritmos de IA e ML. Para cada algoritmo relacionado, há inúmeras variações e adaptações. Como pôde ser verificado, há dezenas de técnicas, cada uma apresenta vantagens, desvantagens e principais usos. É importante que o pesquisador de IA conheça fundamentos de matemática, como álgebra linear, probabilidade e estatística e cálculo, bem como programação de modo a avaliar a melhor ferramenta de IA para cada desafio que se deseja resolver. Há inúmeras bibliotecas disponíveis para Python, para a maioria dos algoritmos de IA, o que pode acelerar o desenvolvimento de novas ferramentas e aplicações.
4. REFERÊNCIAS
[1] CARVALHO, Arnaldo. Redes Neurais Artificiais: Algoritmos poderosos para aplicações de IA e ML. EAILAB, IFSP, Publicado em Abril 03, 2024. Disponível em <https://eailab.labmax.org/2024/04/03/redes-neurais-artificiais-algoritmos-poderosos-para-aplicacoes-de-ia-e-ml/>. Acessado em Jun 20, 2024.
[2] CARVALHO, Arnaldo. 10 Tendências de Aplicação de Inteligência Artificial em 2024! EAILAB, IFSP, Publicado em Nov 28, 2023. Disponível em <https://eailab.labmax.org/2023/11/28/10-tendencias-de-aplicacao-de-inteligencia-artificial-em-2024/>. Acessado em Jun 20, 2024.
[3] RAY, Susmita. A quick review of machine learning algorithms. In: 2019 International conference on machine learning, big data, cloud and parallel computing (COMITCon). IEEE, 2019. p. 35-39.
[4] MAHESH, Batta. Machine learning algorithms- A Review. International Journal of Science and Research (IJSR).[Internet], v. 9, n. 1, p. 381-386, 2020.
[5] BROWNLEE, J. Linear Regression for Machine Learning, Mahine Learning Mastery, Dez 6, 2023. Disponível em <https://machinelearningmastery.com/linear-regression-for-machine-learning/>. Acessado em Jul 7, 2024.
[6] BROWNLEE, J. Logistic Regression for Machine Learning, Mahine Learning Mastery, Dez 6, 2023. Disponível em <https://machinelearningmastery.com/logistic-regression-for-machine-learning/>. Acessado em Jul 7, 2024.
[7] BROWNLEE, J. A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning, Ago 15, 2020. Disponível em <https://machinelearningmastery.com/gentle-introduction-gradient-boosting-algorithm-machine-learning/>. Acessado em Jul 7, 2024.
[8] BROWNLEE, J. Naive Bayes for Machine Learning, Ago 15, 2020. Disponível em <https://machinelearningmastery.com/naive-bayes-for-machine-learning/>. Acessado em Jul 7, 2024.
[9] BROWNLEE, J. A Gentle Introduction to Bayesian Belief Networks, Set 25, 2019. Disponível em <https://machinelearningmastery.com/introduction-to-bayesian-belief-networks/>. Acessado em Jul 7, 2024.
[10] LAWHATRE, P. Gentle Introduction to Markov Chain, Machine Learnig Plus, 2024. Disponível em: <https://www.machinelearningplus.com/markov-chain/>. Acessado em Jul 7, 2024.
[11] BROWNLEE, J. A Gentle Introduction to Markov Chain Monte Carlo for Probability, Set 25, 2019. Disponível em <https://machinelearningmastery.com/markov-chain-monte-carlo-for-probability//>. Acessado em Jul 7, 2024.
[12] CHARBUTY, Bahzad; ABDULAZEEZ, Adnan. Classification based on decision tree algorithm for machine learning. Journal of Applied Science and Technology Trends, v. 2, n. 01, p. 20-28, 2021.
[13] SOMVANSHI, Madan et al. A review of machine learning techniques using decision tree and support vector machine. In: 2016 international conference on computing communication control and automation (ICCUBEA). IEEE, 2016. p. 1-7.
[14] HÜLLERMEIER, Eyke. Fuzzy methods in machine learning and data mining: Status and prospects. Fuzzy sets and Systems, v. 156, n. 3, p. 387-406, 2005.
[15] CARVALHO, Arnaldo. Função de Ativação, o Núcleo da Composição de Neurônios Artificiais, EAILAB, IFSP, 2024. Disponível em: <https://eailab.labmax.org/2024/02/28/funcao-de-ativacao-o-nucleo-da-composicao-de-neuronios-artificiais/>. Acessado em Jun 20, 2024.
[16] CARVALHO, A., JUSTO, J.F., ANGELICO, B.A. et al. Model reference control by recurrent neural network built with paraconsistent neurons for trajectory tracking of a rotary inverted pendulum, Applied Soft Computing, 2022, 109927, ISSN 1568-4946. DOI: 10.1016/j.asoc.2022.109927.
[17] CARVALHO, A., JUSTO, J.F., ANGELICO, B.A. et al., Rotary Inverted Pendulum Identification for Control by Paraconsistent Neural Network, in IEEE Access, 2021. DOI: 10.1109/ACCESS.2021.3080176.
[18] DE CARVALHO JUNIOR, Arnaldo et al. A comprehensive review on paraconsistent annotated evidential logic: Algorithms, Applications, and Perspectives. Engineering Applications of Artificial Intelligence, v. 127, p. 107342, 2024.
[19] GUPTA, Jaya; PATHAK, Sunil; KUMAR, Gireesh. Deep learning (CNN) and transfer learning: a review. In: Journal of Physics: Conference Series. IOP Publishing, 2022. p. 012029.
[20] SAHA, S. A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way, Medium, Dez 2018. Disponível em <https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53>. Acessdo em Jul 12, 2024.
[21] BROWNLEE, J. 10 Clustering Algorithms With Python, Mahine Learning Mastery, Ago 20, 2020. Disponível em <https://machinelearningmastery.com/clustering-algorithms-with-python/>. Acessado em Jul 7, 2024.
[22] TAM, A. 10 Principal Component Analysis for Visualization, Mahine Learning Mastery, Out 27, 2021. Disponível em <https://machinelearningmastery.com/principal-component-analysis-for-visualization/>. Acessado em Jul 7, 2024.
[23] DEEP LEARNING BOOK, Capítulo 58 – Introdução aos Autoencoders, Data Science Academy, 2022. Disponível em <https://www.deeplearningbook.com.br/introducao-aos-autoencoders/>. Acessado em Jul 12, 2024.
[24] DEEP LEARNING BOOK, Capítulo 62 – O Que é Aprendizagem Por Reforço?, Data Science Academy, 2022. Disponível em <https://www.deeplearningbook.com.br/o-que-e-aprendizagem-por-reforco/>. Acessado em Jul 12, 2024.
[25] DEEP LEARNING BOOK, Capítulo 70 – Deep Q-Network e Processos de Decisão de Markov, Data Science Academy, 2022. Disponível em <https://www.deeplearningbook.com.br/deep-q-network-e-processos-de-decisao-de-markov/>. Acessado em Jul 12, 2024.
[26] BROWNLEE, J. K-Nearest Neighbors for Machine Learning, Ago 15, 2020. Disponível em <https://machinelearningmastery.com/markov-chain-monte-carlo-for-probability//>. Acessado em Jul 7, 2024.
[27] KUBRUSLY, J. Introdução ao Machine Learning – Capítulo 4 Floresta Aleatória, Laboratório de Estatística, Universidade Federal Fluminense, 2023. Disponível em: <https://bookdown.org/jessicakubrusly/intr-machine-learning-i/_book/cap-floresta.html>. Acessado em Jul 12, 2024.
[28] SOUZA, I. C. N. Tutorial de aprendizado de máquina SVM – o que é o algoritmo de máquina de vetores de suporte, explicado com exemplos de códigos. FreeCodeCamp, Jun 2024. Disponível em: <https://www.freecodecamp.org/portuguese/news/tutorial-de-aprendizado-de-maquina-svm/>. Acessado em Jul 12, 2024.
[29] BROWNLEE, J. Simple Genetic Algorithm From Scratch in Python, Mahine Learning Mastery, Out 12, 2021. Disponível em <https://machinelearningmastery.com/simple-genetic-algorithm-from-scratch-in-python/>. Acessado em Jul 7, 2024.
[30] DEEP LEARNING BOOK, Capítulo 85 – Transformadores – O Estado da Arte em Processamento de Linguagem Natural, Data Science Academy, 2022. Disponível em <https://www.deeplearningbook.com.br/transformadores-o-estado-da-arte-em-processamento-de-linguagem-natural/>. Acessado em Jul 12, 2024.
[31] ANKIT, U. Transformer Neural Network: Step-By-Step Breakdown of the Beast. Toward Data Science, Medium, Abr 2020. Disponível em: <https://towardsdatascience.com/transformer-neural-network-step-by-step-breakdown-of-the-beast-b3e096dc857f>. Acessado em Jul 12, 2024.
Elaborado Por: Dr. Arnaldo de Carvalho Junior
Publicado em: Jul 13, 2024