


Redes Neurais Artificiais: Algoritmos poderosos para aplicações de IA e ML
- INTRODUÇÃO
A inteligência artificial – IA (artificial intelligence – AI), segundo a Encyclopædia Britannica, é uma disciplina da ciência da computação que pesquisa a capacidade de um recurso computacional executar tarefas comumente associadas a seres inteligentes. O termo é amplo e geralmente aplicado ao desenvolvimento de sistemas e processos com capacidade de raciocinar, classificar, descobrir significado, generalizar ou aprender com experiências passadas [1]. A Inteligência Artificial pode ser dividida em 7 subcampos, conforme Figura 1 [2]:
• Aprendizado de máquina (machine learning – ML), Mineração de Dados e Grandes Dados (Data Mining e Big Data);
• Planejamento Automatizado;
• Sistemas Especialistas (expert systems);
• Processamento de Linguagem Natural (natural language processing – NLP);
• Reconhecimento de fala (speech recognition);
• Robótica;
• Visão Computacional (computer vision).
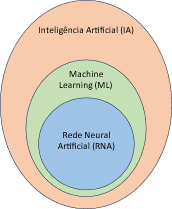
A ML é um ramo da IA (Figura 2), que se preocupa com a implementação de software de computador capaz de aprender autonomamente. Sistemas especialistas e programas de mineração de dados são as aplicações mais comuns para melhorar algoritmos através do uso de aprendizado de máquina [3].
As redes neurais artificiais – RNAs (artificial neural networks – ANN) são técnicas computacionais que apresentam um modelo matemático inspirado na estrutura neural de organismos inteligentes e que adquirem conhecimento através da experiência [4]. Essa estrutura é formada por neurônios artificiais, funções de ativação específicas, conforme apresentado em [5]. As RNAs desempenham papel fundamental nos algoritmos de ML e IA.
2. TIPOS DE REDES NEURAIS ARTIFICIAIS
O aumento do poder computacional das últimas décadas permitiu uma rápida evolução e proposição de diferentes arquiteturas de RNAs para as mais variadas áreas do conhecimento humano [5]. A Figura 3 fornece uma ideia da variedade de configurações de RNAs [6].
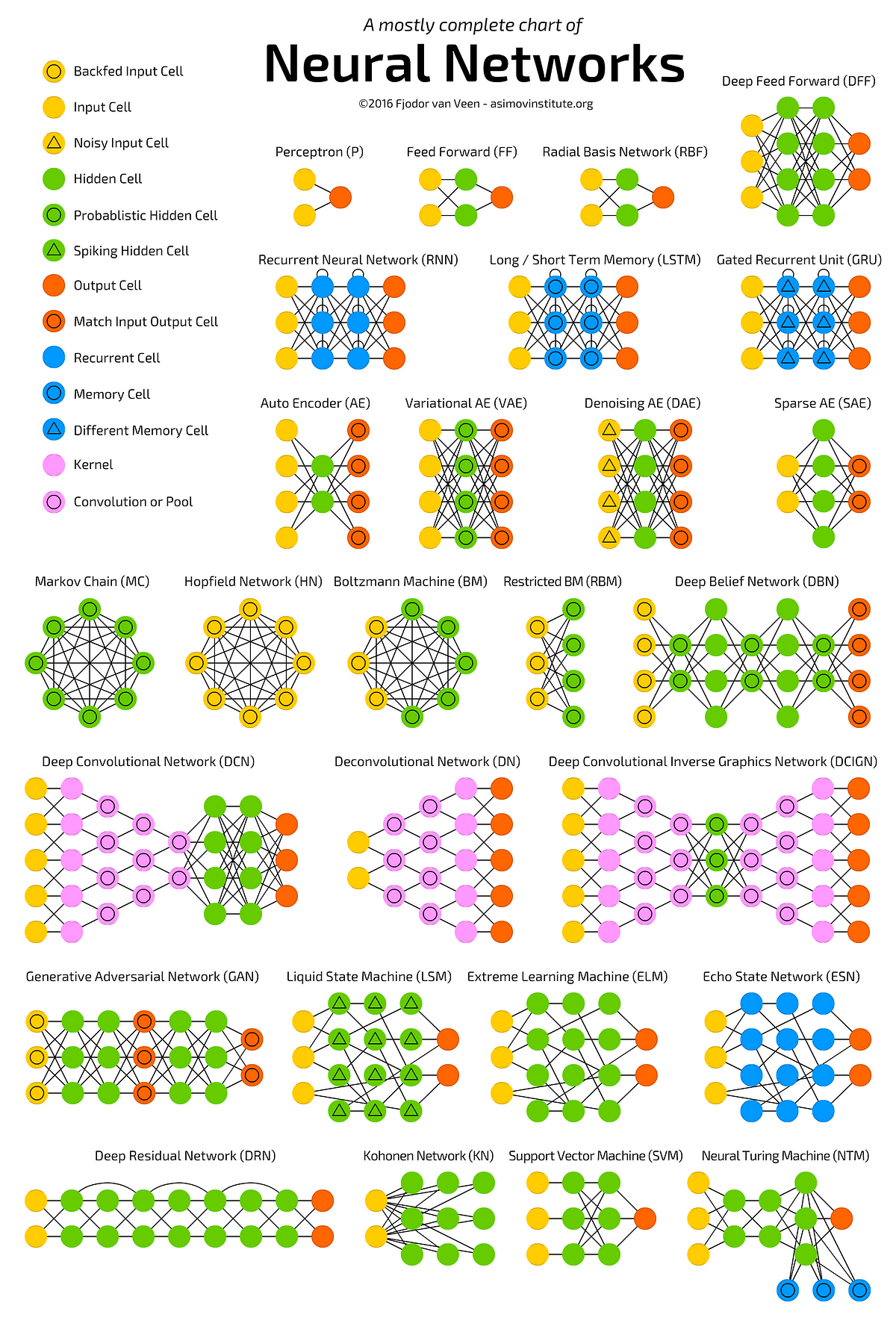
Neste post serão apresentados as RNAs mais comumente empregadas em aplicações de ML.
2.1. Rede Neural Feedforward
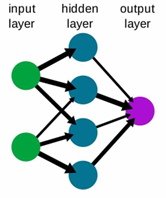
A RNA do tipo feedforward foi uma das primeiras propostas, sendo uma das mais básicas. Nesta RNA, os dados ou a entrada fornecida viajam em uma única direção (forward). Os dados entram na RNA pela camada de entrada (input layer) e saem pela camada de saída (output layer), enquanto camadas ocultas (hidden layer) podem ou não existir. Logo, a rede neural feedforward (FNN) possui apenas uma onda propagada frontalmente sendo geralmente treinadas utilizando-se o método de retropropagação. Podem ser usadas para aproximação de funções e classificação de padrões [6].
2.2. Rede Neural de Base Radial
A rede neural de função base radial (radial basis function neural network – RBFNN) é um tipo de RNA feedforward que faz uso de funções de base radial como funções de ativação nos neurônios da camada oculta. Uma função de base radial é uma função de valor real, cujo valor depende apenas da distância da origem. Embora existam vários tipos de funções de base radial, a função Gaussiana é a mais frequentemente empregada, conforme Eq. 1, a seguir.
 (1)
(1)
Onde (x) é o vetor de entrada, (cj) é o centro da função Gaussiana e hj(x) a saída do neurônio j. A saída da rede é uma combinação linear de funções de base radial das entradas e parâmetros do neurônio. As RBFNN têm muitos usos, incluindo aproximação de funções, previsão de séries temporais, classificação e controle de sistema. O treinamento da RBFNN também é mais rápido do que a FNN utilizando neurônios baseados em sigmoide. Outras características da RBFNN incluem design fácil, boa generalização e robustez para ruído de entrada. Para problemas de aproximação de função, as RBFNN são especialmente recomendadas para superfícies com picos e vales regulares. Uma desvantagem da RBFNN é a sua complexidade, que aumenta à medida que o número de neurônios na camada oculta aumentam. Outro desafio da RBF está no seu algoritmo de treinamento e estrutura, não permitindo modelar um ambiente de sistema fortemente não linear [4].
2.3. Rede Neural Recorrente
A rede neural recorrente (recurrent neural network – RNN) difere da FNN pela direção do fluxo de informações entre as suas camadas. A RNN é uma rede neural artificial bidirecional, pois permite que a saída de alguns nós afete a entrada subsequente para os mesmos nós. Em outras palavras, as RNNs são redes com loops, permitindo que as informações persistam por mais tempo na rede. Sua capacidade de usar o estado interno (memória) para processar sequências arbitrárias de entradas torna as RNN aplicáveis a tarefas como reconhecimento de escrita manual conectada e não segmentada ou reconhecimento de fala.
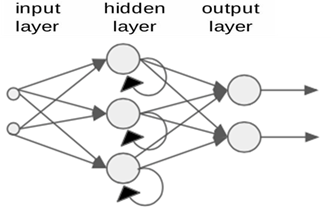
As RNN são muito utilizadas para aplicações que utilizam séries temporais como entrada, como na modelagem e controle de sistemas não lineares, apesar das dificuldades maiores de treinamento do que redes FNN. Um exemplo é o desenvolvimento de um controle por modelo de referência (model reference control – MRC), utilizando RNN com neurônios PAL2v (recurrent paraconsistente neural network – RPNN) para prever a saída futura do controlador de um sistema dinâmico de pêndulo invertido rotativo, apresentando maior robustez e menor esforço do que um controle convencional, em [4].
2.4. LSTM
A rede neural de memória de longo e curto prazo (long short-term memory – LSTM) é uma variação de rede neural recorrente (RNN), que visa lidar com o problema do gradiente de fuga (vanishing gradient) presente em RNNs tradicionais. A unidade LSTM possui uma estrutura em cadeia composta por diferentes blocos de memória chamados células (cells), conforme a Figura 6. As células retêm a informação, enquanto os portões (gates) realizam a manipulação da memória. O cascateamento de unidades LSTM foram a rede neural LSTM, conforme a Figura 7.
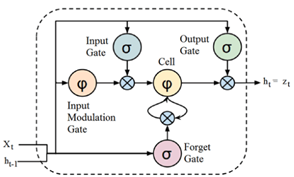
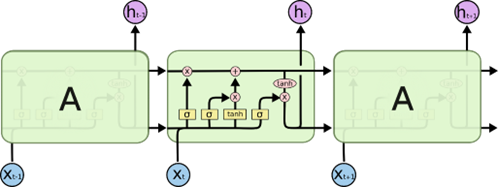
As células retêm a informação, enquanto os portões (gates) realizam a manipulação da memória [8]. Os gates são:
a) Esqueça o portão (Forget Gate): As informações que não são mais úteis são removidas com o forget gate. A entrada no momento específico (xt) e a saída da célula LSTM anterior (ht-1) são alimentadas ao gate e multiplicadas por matrizes de peso, seguidas da adição de um bias, cujo resultado é aplicado a uma função de saída binária [5]. Se para um determinado estado de célula a saída for “0”, a informação é esquecida e para a saída “1”, a informação é retida para uso futuro.
b) Portão de entrada (Input Gate): A adição de informações úteis ao estado da célula é feita pelo input gate. Inicialmente, a informação é regulada usando a função sigmoide [5] que filtra os valores a serem lembrados usando as entradas xt e ht-1, de maneira parecida com o forget gate. Então, mediante uma função de ativação tanh [5] um vetor é criado, fornecendo uma saída limitada a [-1, +1], que contém todos os valores possíveis de xt e ht-1. Os valores do vetor e os valores regulados são multiplicados para obter as informações úteis.
c) Portão de saída (Output Gate): A tarefa de extrair informações úteis do estado da célula atual para ser apresentadas como uma saída é feita pelo output gate. Primeiro, um vetor é gerado aplicando a função de ativação tanh na célula. Então, a informação é regulada usando a função de ativação sigmoide que filtra os valores a serem lembrados usando as entradas xt e ht-1. Os valores do vetor e os valores regulados são multiplicados para serem enviados como uma saída e entrada para a próxima célula.
A LSTM é adequada para classificar, processar e prever séries temporais com intervalos de tempo de duração desconhecida, devido a sua capacidade de lembrar de valores em intervalos arbitrários. Além de aplicações que envolvem predição de saída futura, as redes LSTM têm sido utilizadas com sucesso na modelagem de linguagem, tradução de idiomas, legendas de imagens, geração de texto e chatbots.
2.5. Rede Neural Convolucional
A rede neural convolucional (convolucional neural network – CNN) é um tipo de FNN que aprende uma característica por meio de otimização de filtros. Gradientes de fuga e gradientes de explosão, vistos durante a retropropagação em redes neurais clássicas, são evitados pelo uso de pesos regularizados em menos conexões. Por exemplo, para processar uma imagem de 100×100 pixels, seriam necessários 10.000 pesos para cada neurônio na camada totalmente conectada. No entanto, aplicando kernels de convolução em cascata, apenas 25 neurônios são necessários para processar blocos de tamanho 5×5. Os recursos da camada superior são extraídos de janelas de contexto mais amplas, em comparação com os recursos da camada inferior.
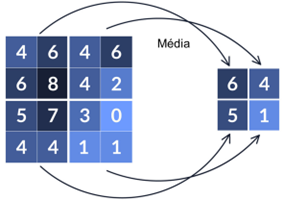
Várias técnicas de convolução podem ser aplicadas, procurando extrair características específicas de um padrão 2D como contorno, contraste, objeto, etc. A Figura 8 apresenta um exemplo de convolução pela média, reduzindo uma matriz 4×4 (16 pixels) em uma matriz 2×2 (4 pixels).
A Figura 9 apresenta uma arquitetura de CNN [10]. Pode-se observar que uma CNN é composta por uma ou mais camadas convolucionais (hidden layers), seguidas por uma ou mais camadas de neurônios totalmente conectados, para a etapa de classificação, como uma rede FNN padrão.
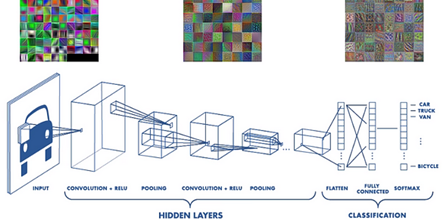
A arquitetura de uma CNN é projetada para aproveitar a estrutura 2D de uma imagem de entrada (ou de um sinal contínuo transformado em padrão 2D sendo invariantes à mudança (shift invariant) ou invariantes em espaço (space invariant). Outro benefício das CNNs é que elas são mais fáceis de treinar e possuem muito menos parâmetros do que redes totalmente conectadas com o mesmo número de unidades ocultas.
Aplicações de CNN incluem reconhecimento, segmentação e classificação de imagem e vídeo; sistemas de recomendação; análise de imagem médica; processamento de linguagem natural; interfaces cérebro-computador e séries temporais como financeiras, por exemplo. Uma ferramenta que utiliza CNN para identificação e classificação de imagens é o Edge Impulse [11]. Exemplos de aplicação podem ser observados nos artigos relacionados em [12].
2.6. Redes Neurais de Aprendizado Profundo
Redes Neurais de aprendizado profundo (deep learning neural network – DLNN) ou simplesmente redes neurais profundas (deep neural network – DNN) são redes neurais (FNN, RNN, CNN, entre outras) que possuem múltiplas camadas intermediárias. Embora possam existir diferentes topologias, a maioria dos modelos modernos de aprendizagem profunda são baseados em CNN. A Figura 10 apresenta uma arquitetura de DNN.
O aprendizado profundo é uma classe de algoritmos de aprendizado de máquina que utiliza múltiplas camadas para extrair progressivamente recursos de nível superior da entrada bruta. Um exemplo de aplicação de DNN é no processamento de imagens, onde as camadas inferiores podem identificar bordas e contornos, enquanto as camadas superiores podem identificar os conceitos relevantes para um ser humano, como dígitos, letras ou rostos.
Como pode ser observado pela Figura 10, as DNNs são mais complexas que as redes neurais convencionais, com algoritmos mais densos e exigindo maior poder de processamento para o seu treinamento. Entretanto, as DNNs têm sido amplamente utilizadas no reconhecimento de imagens, processamento de linguagem natural, predições financeiras, conversão de textos em imagens, entre outras aplicações. Uma boa revisão sobre algoritmos de aprendizado profundo e suas aplicações está disponível em [15].
3. CONSIDERAÇÕES FINAIS
As redes neurais artificiais são um poderoso instrumento para o sucesso do machine learning e da inteligência artificial. Este é um ramo da ciência da computação em acelerada evolução, com uma variedade virtualmente infinita de RNAs propostas. Este post apresentou algumas das arquiteturas de RNAs mais utilizadas, as suas características principais e potencial de aplicações em inteligência artificial. Em resumo, as FNN podem ser usadas em aproximação de funções e classificação de sinais, as RNN e suas variações (LSTM, por exemplo) utilizam séries temporais para previsão de saída futura. Já as CNN e suas variações são utilizadas em visão computacional, como no tratamento e classificação de imagens.
REFERÊNCIAS
[1] COPELAND, B.J. Artificial Intelligence. Encyclopedia Britannica, 1 Apr. 2024. Disponível em: https://www.britannica.com/technology/artificial-intelligence. Acessado em Abr 1, 2024.
[2] KAYID, A. The role of Artificial Intelligence in future technology. Department of Computer Science, The German University in Cairo, 2020. Disponível em: The-role-of-Artificial-Intelligence-in-future-technology.pdf (researchgate.net)
[3] SHINDE, P. P. and SHAH, S. A Review of Machine Learning and Deep Learning Applications, 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 2018, pp. 1-6. DOI: 10.1109/ICCUBEA.2018.8697857.
[4] CARVALHO, A., JUSTO, J.F., ANGELICO, B.A. et al. Model reference control by recurrent neural network built with paraconsistent neurons for trajectory tracking of a rotary inverted pendulum, Applied Soft Computing, 2022, 109927, ISSN 1568-4946. DOI: 10.1016/j.asoc.2022.109927.
[5] CARVALHO, A. Função de Ativação, o Núcleo da Composição de Neurônios Artificiais, EAILAB, IFSP, 2024. Disponível em: https://eailab.labmax.org/2024/02/28/funcao-de-ativacao-o-nucleo-da-composicao-de-neuronios-artificiais/
[6] CARVALHO, A., JUSTO, J.F., ANGELICO, B.A. et al., Rotary Inverted Pendulum Identification for Control by Paraconsistent Neural Network, in IEEE Access, 2021. DOI: 10.1109/ACCESS.2021.3080176.
[7] MONTAZER, G. A. et al. Radial basis function neural networks: A review. Computer Reviews. Journal, v. 1, n. 1, p. 52-74, 2018. Disponivel em: https://www.ise.ncsu.edu/fuzzy-neural/wp-content/uploads/sites/9/2022/08/RBFNN.pdf
[8] DEEP LEARNING BOOK. Capítulo 51 – Arquitetura de Redes Neurais Long Short Term Memory (LSTM). Disponível em: https://www.deeplearningbook.com.br/arquitetura-de-redes-neurais-long-short-term-memory/. Acessado em Abr 03, 2024.
[9] OLAH, C. Understanding LSTM Networks, Colah’s blog. Aug 2015. Disponível em: https://colah.github.io/posts/2015-08-Understanding-LSTMs/. Acessado em Abr 03, 2024.
[10] YEOLA, C. Convolutional Neural Network (CNN) In Deep Learning, Feb, 2022. Disponível em: https://python.plainenglish.io/convolution-neural-network-cnn-in-deep-learning-77f5ab457166. Acessado em Abr 03, 2024.
[11] EDGE IMPULSE. Build, train, optimize, ai for the edge. Edge Impulse. Disponível em: https://edgeimpulse.com. Acessado em abr 03, 2024.
[12] CARVALHO, A. EAILAB inicia atividades com produção intensa de trabalhos. Nov, 2023. Disponível em: https://eailab.labmax.org/2023/11/16/eailab-inicia-atividades-com-producao-intensa-de-trabalhos/. Acessado em Abr 03, 2024.
[13] CHIEN, J-T. Chapter 7 – Deep Neural Network, Editor(s): Jen-Tzung Chien, Source Separation and Machine Learning, Academic Press, 2019, 259-320 p, ISBN 9780128177969, DOI: 10.1016/B978-0-12-804566-4.00019-X. Disponível em: https://www.sciencedirect.com/science/article/pii/B978012804566400019X.
[14] NIELSEN, M. A. Neural networks and deep learning. San Francisco, CA, USA: Determination press, 2015.
[15] SHINDE, Pramila P.; SHAH, Seema. A review of machine learning and deep learning applications. In: 2018 Fourth international conference on computing communication control and automation (ICCUBEA). IEEE, 2018. p. 1-6. DOI: 10.1109/ICCUBEA.2018.869.
Elaborado Por: Dr. Arnaldo de Carvalho Junior
Publicado em: Abr 03, 2024