


Transformers: A Arquitetura que revolucionou a IA Contemporânea
Por. Dr. Arnaldo de Carvalho Junior
1.INTRODUÇÃO
Na área de processamento de linguagem natural – PLN (Natural Language Processing – NLP), a grande ruptura no desenvolvimento da inteligência artificial (IA) ocorreu com a arquitetura de aprendizado profundo (Deep Learning – DL), chamada transformador (Transformer). Essa arquitetura foi proposta por pesquisadores do Google, até de forma modesta, em um artigo “preprint” de 2017, chamado “Attention is all you need!” [1].
As redes Transformers permitiram o surgimento dos Modelos de Linguagem de Grande Escala (Large languagem Models – LLMs), capazes de gerar textos coerentes, responder perguntas, resumir documentos e auxiliar na programação.
Os LLMs operam prevendo a próxima palavra mais provável em um contexto, o que explica tanto seu poder quanto suas limitações. Isso permitiu a construção de arquiteturas complexas de IA Generativa que se vê hoje, capaz de criar conteúdo (texto, códigos, áudios, vídeos, …) e até atendentes autônomos orientados a objetivos, chamados IA Agencial ou Agentica (Agentic AI) [2].
2. REDES TRANSFORMER: UMA EXPLICAÇÃO SIMPLES
As redes Transformer são uma arquitetura de redes neurais desenvolvida para lidar de forma eficiente com dados sequenciais, como textos, sinais e códigos. Eles introduzem uma mudança de paradigma ao eliminar a recorrência e utilizar mecanismos de atenção.
Diferentemente de arquiteturas mais antigas, como redes neurais recorrentes (Recurrent Neural Networks
– RNNs), os Transformers processam todos os elementos da sequência em paralelo, o que torna o treinamento mais rápido e escalável. Essa mudança explica o por que os Transformes se tornaram a espinha dorsal da IA Generativa contemporânea [3].
2.1 Principais Blocos de Uma Rede Transformer
A Figura 1 apresenta a arquitetura de uma rede Transformer [1]. Ela é formada por blocos empilhados, que se repetem ao longo da arquitetura.
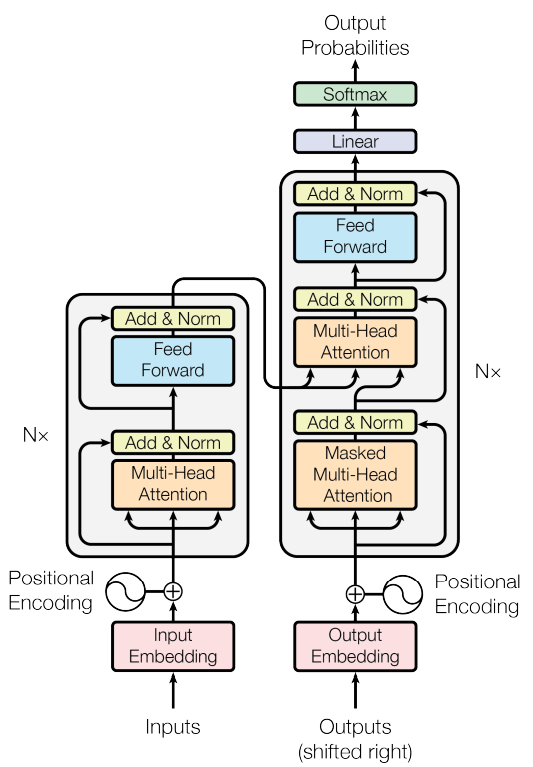
Fonte: Adaptado de [1].
Os principais componentes são [4]:
- Camada de Embedding: Cada palavra, símbolo ou unidade de entrada é convertida em um vetor numérico contínuo, chamado embedding, que representa seu significado de forma matemática.
- Codificação Posicional (Positional Encoding): Como o Transformer não possui memória sequencial explícita, ele adiciona informações sobre a posição dos tokens na sequência, permitindo distinguir, por exemplo, o início e o fim de uma frase.
- Mecanismo de Atenção (Self-Attention): Esse é o núcleo do Transformer. Ele permite que cada token “preste atenção” a outros tokens da sequência, atribuindo pesos diferentes conforme a relevância contextual. Assim, o modelo consegue capturar relações de longo alcance em um texto.
- Atenção Multi-Cabeça (Multi-Head Attention): Em vez de uma única atenção, o modelo utiliza várias atenções em paralelo, permitindo capturar diferentes tipos de relações semânticas e sintáticas ao mesmo tempo.
- Redes Feedforward: Após a atenção, cada token passa por uma pequena rede neural totalmente conectada, que transforma os vetores e aumenta a capacidade de representação do modelo.
- Normalização e Conexões Residuais: Esses mecanismos ajudam a estabilizar o treinamento e permitem que a informação flua melhor pelas camadas profundas da rede.
- Saída Camada Densa Linear + Softmax: A camada de rede neural densa linear possui o tamanho do vocabulário. Logo após, a função Softmax (ou função exponencial normalizada) é aplicada, gerando a distribuição de probabilidades de cada uma das palavras.
2.2 O que é um token para os Transformers ?
Um token é a unidade básica de processamento usada pelos Transformers . Dependendo do modelo, um
token pode representar uma palavra inteira, parte de uma palavra (subpalavra), um caractere ou até símbolos especiais [5].
Por exemplo, a palavra “aprendizado” pode ser dividida em vários tokens menores. O modelo não “entende” palavras diretamente, mas sim sequências de tokens representadas por números.
Esses tokens são então transformados em incorporações (embeddings) e processados pelo mecanismo de atenção, permitindo ao modelo aprender padrões linguísticos, semânticos e contextuais.
Nota:
Embora os Transformers sejam extremamente eficazes em tarefas de linguagem e geração de conteúdo, eles não possuem compreensão ou consciência, operando exclusivamente por meio de padrões estatísticos aprendidos a partir de grandes volumes de dados.
Um tutorial de uso e exemplo de Rede Transformer em Python está disponível respectivamente nas referências [5] e [6]. Este exemplo pode ser executado diretamente via a plataforma Google Colab. Note o tempo que leva para executar o treinamento do Transformer neste exemplo.
3. CARACTERÍSTICAS DOS TRANSFORMERS
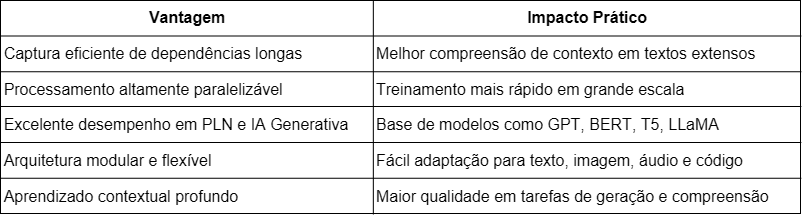
A Tabela 1 apresenta as características principais dos Transformers.

4. TRANSFORMER: USAR OU NÃO USAR?
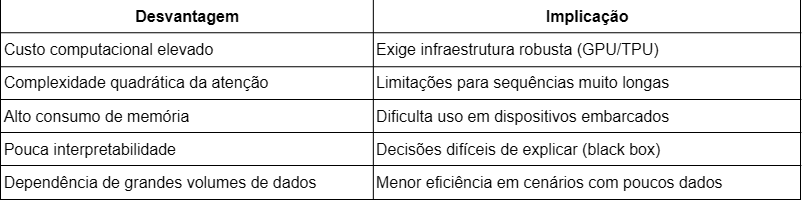
Apesar de revolucionária, nem sempre os Transformers são a melhor tecnologia a ser aplicada. As Tabelas 2 e 3 apresentam respectivamente as vantagens e desvantagens desta tecnologia revolucionária.
4.1. Use Transformers quando…
✔ O problema envolve sequências complexas
- Texto longo, documentos, código-fonte, séries multimodais.
- Ex.: chatbots, análise jurídica, sumarização de relatórios, tradução automática.
✔ O contexto global é relevante
- Relações entre elementos distantes da sequência são importantes.
- Ex.: interpretação semântica, raciocínio contextual, PLN.
✔ Há disponibilidade de dados em grande escala
- Grandes volumes de dados rotulados ou não rotulados.
- Ex.: treinamento ou ajuste fino (fine-tuning) de LLMs.
✔ Existe infraestrutura computacional adequada
- GPUs/TPUs, ambientes em nuvem ou clusters.
- Ex.: empresas, universidades, centros de pesquisa.
✔ O objetivo envolve geração de conteúdo
- Texto, imagem, código, áudio ou múltiplas modalidades.
- Ex.: IA Generativa, assistentes virtuais, recomendação contextual.
4.2. Evite os Transformers quando…
✖ O problema é simples ou bem estruturado
- Relações diretas entre entrada e saída.
- Ex.: regressão linear, classificação tabular simples.
✖ Os dados são escassos
- Poucos exemplos disponíveis para treinamento.
- Ex.: pequenos datasets industriais ou clínicos.
✖ Há restrições severas de recursos
- Sistemas embarcados, computação de borda (edge computing), Internet das Coisas (Internet of Things – IoT).
- Ex.: sensores, dispositivos móveis de baixo consumo.
✖ A interpretabilidade é requisito central
- Ambientes regulados ou críticos.
- Ex.: decisões médicas, jurídicas ou financeiras explicáveis.
✖ A latência precisa ser mínima
- Respostas em tempo real com custo computacional reduzido.
- Ex.: controle industrial em tempo real.
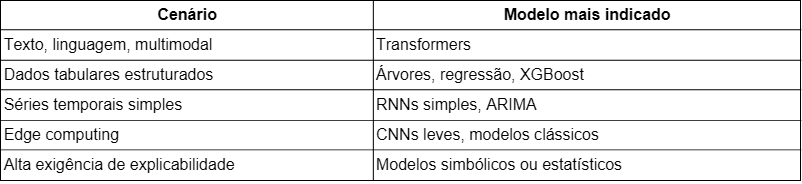
A Tabela 4 traz aplicações mais indicadas para os Transformers e outros modelos de IA.
5. CONSIDERAÇÕES FINAIS
Os Transformers são de fato um ponto de virada de chave e o propulsor para a revolução da IA contemporânea. Os Transformers oferecem desempenho superior e escalabilidade, porém com o custo de maior complexidade computacional e desafios de interpretabilidade. Assim o uso do Transformer deve ser estrategicamente avaliado conforme o contexto, recursos disponíveis e objetivos a serem atingidos.
REFERÊNCIAS
[1] VASWANI, Ashish et al. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, 6000–6010. Red Hook, NY, USA: Curran Associates Inc. ISBN 9781510860964.
[2] CARVALHO JUNIOR, Arnaldo De. Evolução da IA Tradicional para a IA Generativa e Agencial. EAILab, Labmax, IFSP, 2026. Disponível em: https://eailab.labmax.org/2026/01/26/evolucao-da-ia-tradicional-para-a-ia-generativa-e-agencial/. Acesso em: Fevereiro 05, 2026.
[3] DEEP LEARNING BOOK. Capítulo 85 – Transformadores – O Estado da Arte em Processamento de Linguagem Natural, Data Science Academy, 2025. Disponível em: https://www.deeplearningbook.com.br/transformadores-o-estado-da-arte-em-processamento-de-linguagem-natural/. Acesso em: Fevereiro 05, 2026.
[4] DE PAIVA, Eduardo Soares; PEREIRA, Fernando Sola. Capítulo 2 – Deep learning para processamento de linguagem natural, Tópicos Especiais em Sistemas de Informação, Minicursos SBSI, Sociedade Brasileira da Computação, 2022. Disponível em: https://books-sol.sbc.org.br/index.php/sbc/catalog/view/86/379/654. Acesso em: Fevereiro 05, 2026.
[5] CARVALHO JUNIOR, Arnaldo De. Arquitetura dos Transformadores. EIALab-IFSP, Repositório GitHub, 2025. Disponível em: https://github.com/EAILAB-IFSP/AI_ALGORITHMS/blob/AI_Algorithms/Arquitetura%20dos%20Transformadores.pdf. Acesso em: Fevereiro 05, 2026.
[6] CARVALHO JUNIOR, Arnaldo De. Transformer Using Pytorch. EAILab-IFSP, 2025. Disponível em: https://colab.research.google.com/drive/13IkORfUEtOwmMC4idP1g-CukSXlGqEds?usp=sharing. Acesso em: Fevereiro 05, 2026.
[7] CARVALHO JUNIOR, Arnaldo De. Principais Algoritmos Utilizados em Inteligência Artificial, EAILAB, IFSP, 2024. Disponível em: https://eailab.labmax.org/2024/07/13/principais-algoritmos-de-inteligencia-artificial-utilizados/. Acesso em: Fevereiro 05, 2026.
[8] CARVALHO JUNIOR, Arnaldo De. Redes Neurais Artificiais: Algoritmos poderosos para aplicações de IA e ML. EAILAB, IFSP, 2024. Disponível em: https://eailab.labmax.org/2024/04/03/redes-neurais-artificiais-algoritmos-poderosos-para-aplicacoes-de-ia-e-ml/. Acesso em: Fevereiro 05, 2026.
[9] CARVALHO JUNIOR, Arnaldo De. O Poder Das CNNs Em Aplicações de ML Envolvendo Identificação e Classificação de Imagens. EAILAB, IFSP, 2024. Disponível em: https://eailab.labmax.org/2024/08/13/o-poder-das-cnns-em-aplicacoes-de-ml-envolvendo-identificacao-e-classificacao-de-imagens/. Acesso em: Fevereiro 05, 2026.