


Métricas de Desempenho em Modelos de IA (parte 1)
Por: Dr. Arnaldo de Carvalho Junior
1. INTRODUÇÃO
Medir o desempenho do modelo de Inteligência Artificial (IA) é fundamental para garantir que os sistemas de IA ofereçam resultados precisos, confiáveis e justos, e que se alinhem aos objetivos desejados [1].
Mas como se verifica o desempenho de um modelo de IA?
Medir o desempenho da IA requer uma abordagem estruturada, combinando os principais indicadores de desempenho (key performance indicators – KPIs) com conhecimentos técnicos para avaliar até que ponto os sistemas de IA se alinham com os objetivos desejados. Para isso existem métricas diretas, indiretas e éticas [2].
a) Métricas Diretas: ou métricas técnicas, avaliam a saída do modelo de IA comparando-o com a verdade fundamental. Essas métricas são essenciais para determinar a capacidade do modelo de fazer previsões precisas e para garantir alta qualidade do modelo [2].
b) Métricas Indiretas: não estão vinculadas diretamente à saída do modelo de IA, mas refletem como as capacidades de IA impactam objetivos de aplicação mais amplos. Exemplo: satisfação do usuário/cliente, redução de custos, aumento de receitas, eficiência operacional, etc [2].
c) Métricas Éticas: ou IA responsável, são um conjunto de métricas usadas para avaliar se um modelo de IA defende a justiça, esta em conformidade com sistemas regulatórios, evita a discriminação e mantém a transparência em seu processo de tomada de decisão. A IA responsável é guiada por três princípios fundamentais: precisão, responsabilidade e transparência. Essas métricas ajudam as organizações a garantir que suas iniciativas de IA se alinhem com os regulamentos legais, as normas sociais e seus próprios valores de negócios. São especialmente críticas em modelos de aprendizado de máquina (machine learning – ML) de alto impacto, onde decisões injustas podem implicar em perdas financeiras, de reputação ou problemas legais [2]. Consulte [3] para saber mais.
Neste post serão avaliados apenas as métricas diretas. É importante notar que nenhum modelo de IA está correto. Então, considerando-se as métricas diretas, melhor o modelo, melhor ele se ajusta aos dados. É tão simples quanto isso. Há muitas métricas diretas, como serão apresentados na continuidade deste post.
Nesta primeira parte serão avaliadas as métricas diretas para modelos de classificação, que usadas quando a variável de destino consiste em rótulos discretos. Exemplo: verdadeiro / falso, bom / ruim, classes A / B / C, etc [2]. Já na parte 2 serão avaliadas as métricas diretas para modelos de regressão.
2. MATRIZ DE CONFUSÃO
Para testar o desempenho de um modelo de classificação, uma matriz de confusão pode ser usada [1]. Em palavras simples, é uma matriz que compreende instâncias de eventos previstos e reais, conforme a Figura 1. O eixo horizontal indica o valor atual enquanto que o eixo vertical indica o previsto.
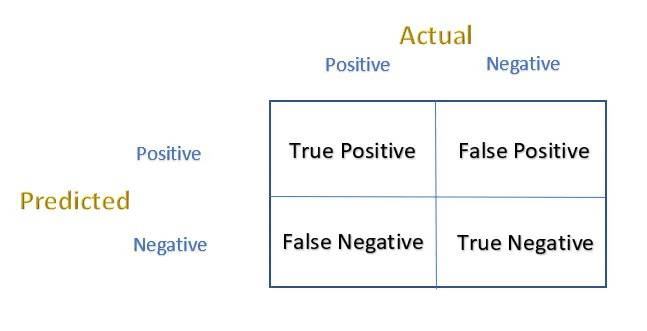
Fonte: Adaptado de [1].
Os quatro termos da Figura 1 são:
a) Verdadeiro Positivo (true positive – TP): Qualquer evento positivo que tenha sido corretamente previsto. Por exemplo: Passar em um exame (positive event) e foi previsto corretamente.
b) Verdadeiro Negativo (true negative – TN): Qualquer evento negativo que tenha sido corretamente previsto. Por exemplo: Não passar em um exame (negative event) e foi previsto corretamente como falho (failed).
c) Falso Positivo (false positive – FP): Qualquer evento negativo que tenha sido previsto positivo. Por exemplo: O paciente não está tendo nenhuma doença. Mas os resultados do teste disseram (previsto) a pessoa está infectada. Isto pode ter os efeitos nocivos de “ser submetido desnecessariamente a tratamento médico indesejado”.
d) Falso Negativo (false negative – FN): Qualquer evento positivo que tenha sido previsto como negativo. Por exemplo: Há uma ameaça a um local público e a equipe de inteligência não consegue identificá-lo, ou seja, denunciá-lo como não uma ameaça. Isso pode ser um problema sério.
3. MÉTRICAS PARA MODELOS DE CLASSIFICAÇÃO
São usadas quando a variável de destino consiste em rótulos discretos. Exemplo: verdadeiro / falso, bom / ruim, classes A / B / C, etc [2]. Os principais tipos são:
a) Precisão: Mede a proporção de previsões positivas que estavam realmente corretas. É a proporção entre positivos verdadeiros (TP) e casos previstos como positivos. Útil quando o custo dos falsos positivos (FP) é alto (e, por exemplo, diagnóstico da doença). É dada pela Equação (1) à seguir:
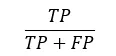
b) Recall: Mede a proporção de positivos reais que foram corretamente identificados. Importante ao perder um verdadeiro positivo é caro (exemplo: detecção de fraude). O recall mede a quantidade de vezes que o modelo de IA acerta em relação ao total de vezes que ele deveria ter acertado. É dada pela Equação (2) a seguir:
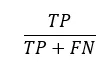
O Recall é também chamado de Sensibilidade (Sensitivity) ou Taxa de Positivos Verdadeiros (True Positive Rate – TPR). Indica a proporção entre eventos positivos corretamente previstos para o total de eventos positivos.
O numerador, TP, representa o número de verdadeiros positivos (true positive), enquanto o denominador (TP + FN) (true positive + false negative) representa o número total de casos positivos reais no conjunto de dados. Ao dividir o número de verdadeiros positivos pela soma de verdadeiros positivos e falsos negativos, obtemos o valor da sensibilidade [1].
Na Ciência, Sensibilidade é a capacidade de identificar corretamente casos positivos. A Sensibilidade, também chamada de taxa positiva ou recordação positiva, é uma medição estatística que determina a proporção de casos positivos reais corretamente identificados por um modelo de aprendizado de máquina. Em outras palavras, a Sensibilidade quantifica a capacidade do modelo de detectar corretamente as instâncias positivas dentro de um conjunto de dados [1].
A Sensibilidade é uma métrica crítica no ML, pois reflete a capacidade do modelo de detectar corretamente instâncias positivas dentro de um conjunto de dados. É especialmente importante em aplicações em que a identificação de casos positivos verdadeiros é de extrema importância, como diagnóstico médico, detecção de fraude ou detecção de anomalia [1],[4].
c) Taxa negativa verdadeira (true negative rate – TNR): Também chamada de Especificidade (Specificity), indica com que frequência o modelo previu os eventos negativos corretamente. Ela avalia a capacidade do modelo de identificar corretamente a ausência da variável de destino em um conjunto de dados. Pode ser calculada como a relação de eventos negativos corretamente previstos (true negative – TN) corretamente e o total de eventos negativos [1]. A Especificidade é dada pela Equação (3) a seguir:
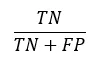
Para entender a Especificidade, é necessário entender o conceito de verdadeiros negativos (TN) e falsos positivos (false positive – FP). Os verdadeiros negativos representam os casos em que o modelo de IA classifica corretamente as instâncias como negativas, enquanto falsos positivos ocorrem quando o modelo identifica incorretamente os casos negativos como positivos [1],[4].
O numerador, TN, representa o número de negativos verdadeiros, enquanto o denominador (TN + FP) representa o número total de casos negativos reais no conjunto de dados. Ao dividir o número de negativos verdadeiros pela soma de verdadeiros negativos e falsos positivos, obtêm-se o valor da Especificidade [4].
A Especificidade é particularmente valiosa em cenários em que a identificação correta de casos negativos é crítica. Por exemplo, em exames médicos, a Especificidade mede a capacidade do modelo de identificar corretamente indivíduos sem uma doença ou condição específica. Um alto valor de Especificidade implica que o modelo pode efetivamente filtrar indivíduos que são verdadeiramente negativos, reduzindo as chances de falsos positivos e minimizando intervenções ou tratamentos desnecessários [4].
d) Taxa de Falsos Positivos (FPR): Porcentagem de instâncias negativas classificadas incorretamente como positivas. Pode ser descrita como: FPR = 1- Especificidade. Indica com que frequência o modelo classificou os eventos negativos como positivos. A proporção de eventos positivos denominados incorretamente em relação ao total de eventos negativos. Útil para compreender riscos potenciais, especialmente em sistemas de IA implantados em domínios sensíveis como finanças ou saúde [4]. A FPR é dada pela equação (4) a seguir:
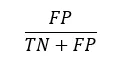
e) Acurácia (Accuracy): mede a frequência de vezes em que o modelo previu corretamente. A proporção dos casos verdadeiros para todos os casos. É dada pela Equação (5) à seguir:
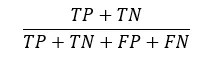
f) Pontuação F1 (F1 Score): Média harmônica que combina precisão e recall, equilibrando a troca entre falsos positivos e falsos negativos. É dada pela Equação (6) a seguir:
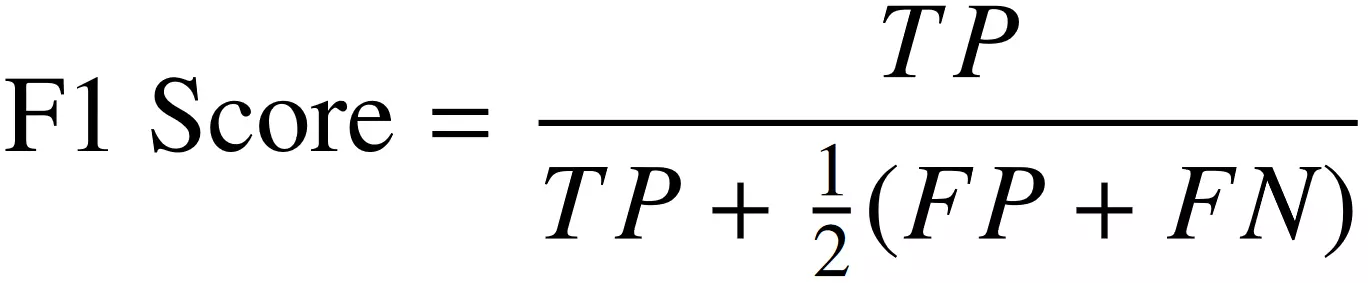
1. Sensibilidade refere-se a quanto bom todos os eventos positivos atuais estão em previstos eventos positivos.
g) ROC e AUC: Deve haver um limite, um valor de limiar, que ajuda o modelo de IA a classificar. A curva característica do operador receptor (receiver operator characteristic curve – ROC) ajuda a decidir o melhor valor limite.
A curva ROC é basicamente um gráfico traçado entre a taxa de verdadeiros positivos (TP) e a taxa de falsos positivos (FP). Portanto, é um gráfico entre a frequência com que um modelo prevê eventos positivos como positivos e a frequência com que um modelo prevê eventos negativos como positivos [2].
A Área sob a curva (area under curve – AUC) é uma das métricas amplamente usadas e basicamente usada para classificação binária. A AUC de um classificador é definida como a probabilidade de um modelo classificar (rank) um exemplo positivo escolhido aleatoriamente maior que um exemplo negativo [2].
4. APLICAÇÕES
Exemplo 1: Suponha que um modelo de IA classificou 100 tumores como maligno (a classe positiva) ou benigno (a classe negativa):
a) Verdadeiro Positivo (TP): Realidade – maligno, modelo de ML previsto – maligno. Número de resultados TP igual a 1.
b) Falso Positivo (FP): Realidade – benigno, modelo de ML previsto – maligno. Número de resultados FP igual a 1.
c) Falso Negativo (FN): Realidade – maligno, modelo de ML previsto – benigno. Número de resultados FN igual a 8.
d) Verdadeiro Negativo (TN): Realidade – benigno, modelo de ML previsto – benigno. Número de resultados TN igual a 90.
Aplicando-se as Equações (1) a (6), tem-se:
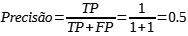
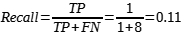
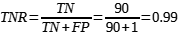
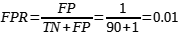
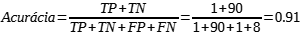
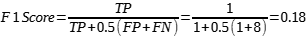
A Figura 2 apresenta a curva ROC para este exemplo [1]. O modelo ao longo da linha tracejada seria o pior classificador. Não se pode discriminar entre as classes. A AUC seria 0.5 neste caso. O modelo ao longo da linha verde paralela ao eixo x na parte superior é o melhor modelo. A AUC seria 1. Classifica perfeitamente os eventos positivos e negativos. Qualquer modelo ou curva (curve) entre estes dois terá uma área maior que 0.5 e menor que 1. Isto resulta na sobreposição de classes e, portanto, são introduzidos erros do Tipo 1 e do Tipo 2.
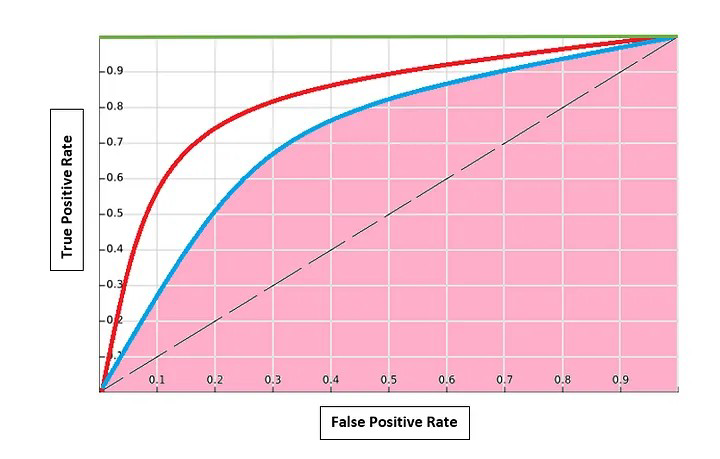
Fonte: Adaptado de [2].
Para diferentes limiares, é calculada a Sensibilidade e o FPR (1- Especificidade). FP baixo significa negativos verdadeiros mais altos. Uma curva é traçada. Dependendo de quantos Falsos Positivos aceitar, o limite é selecionado.
Para comparar modelos, aquele com AUC maior oferece o melhor. Na Figura 2, o modelo da curva vermelha é melhor que o da linha azul. Em alguns casos, por exemplo, quando se tem muitos casos negativos, pode-se optar pela Precisão em caso de Falso Positivo. Para isso o pesquisador deve saber qual é o seu objetivo primeiro.
Exemplo 2: A Figura 3 apresenta 6 imagens com a respectiva classificação [5].

Fonte: Adaptado de [5].
A Figura 4 apresenta a matriz de confusão com classificações perfeitas e imperfeitas.
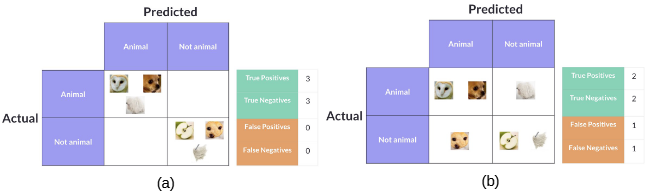
Fonte: Adaptado de [5].
A Figura 5 apresenta a situação em que um modelo classifica todas as figuras como “Animal”.
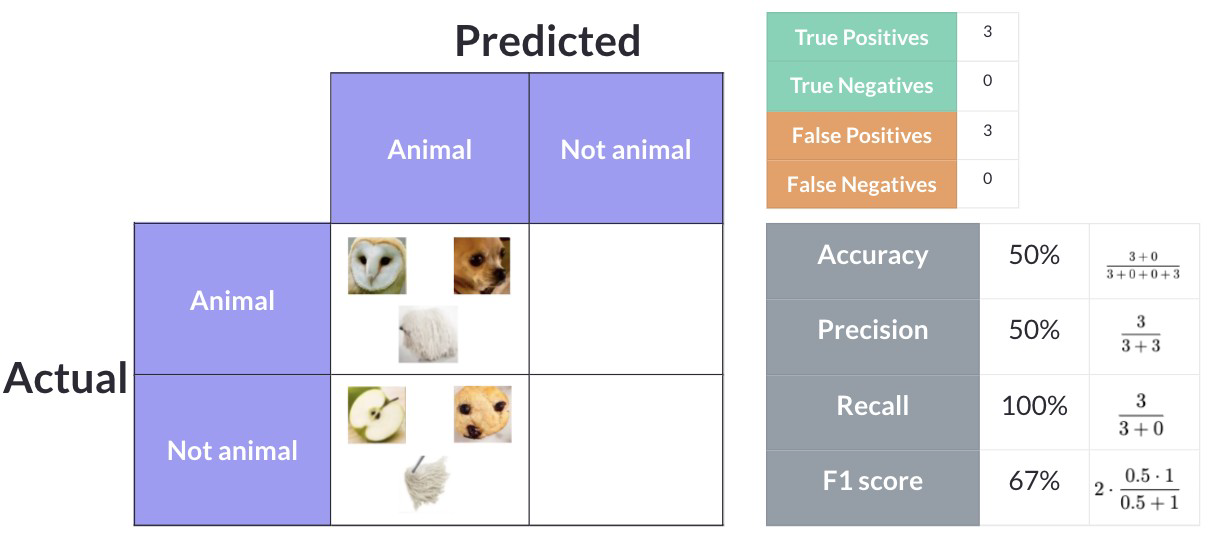
A Figura 6 apresenta a situação em que um modelo de IA classifica todas as imagens como “Não Animal (Not Animal)”.
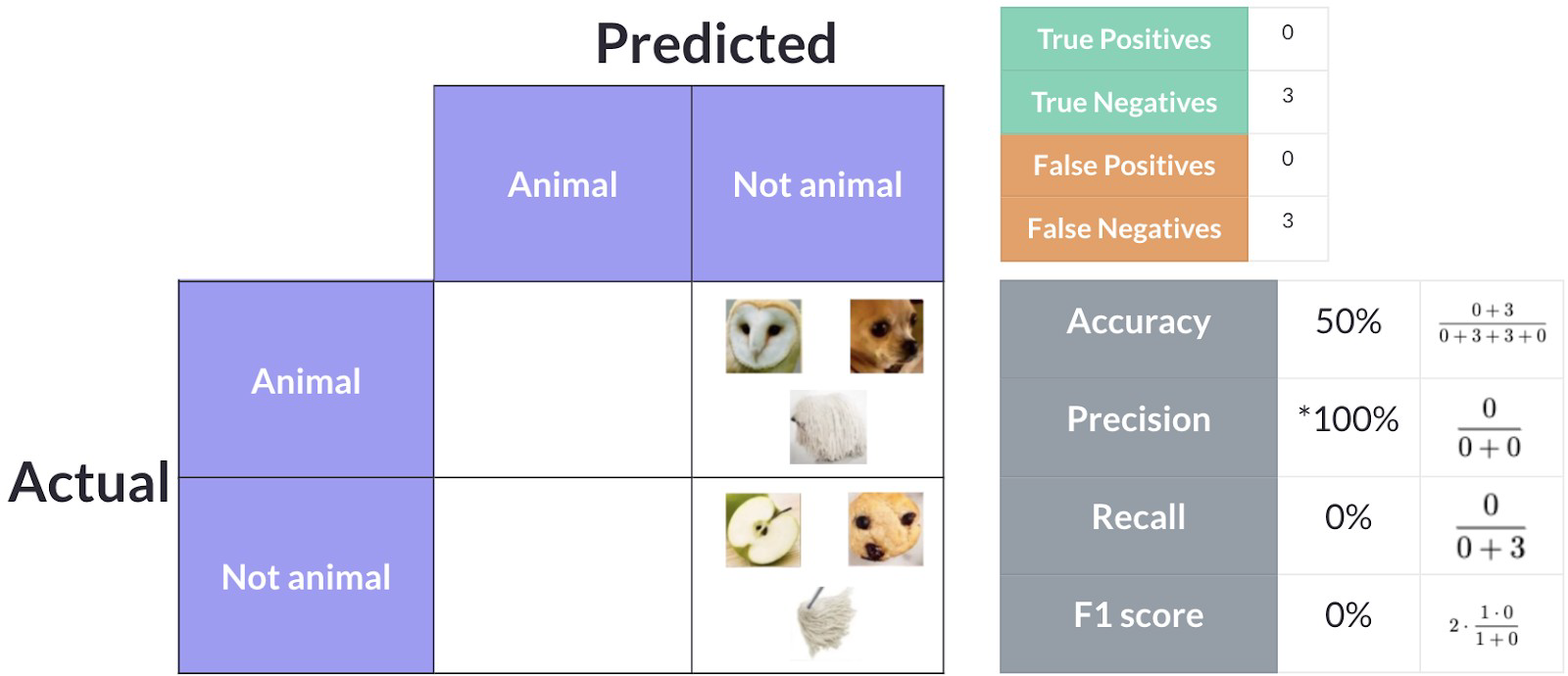
Fonte: Adaptado de [5].
A Figura 7 apresenta uma situação em que há mais predições como “Not Animal” e menos como “Animal”. Já a Figura 8 apresenta o exemplo oposto, com mais predições classificadas como “Animal” do que como “Not Animal”.
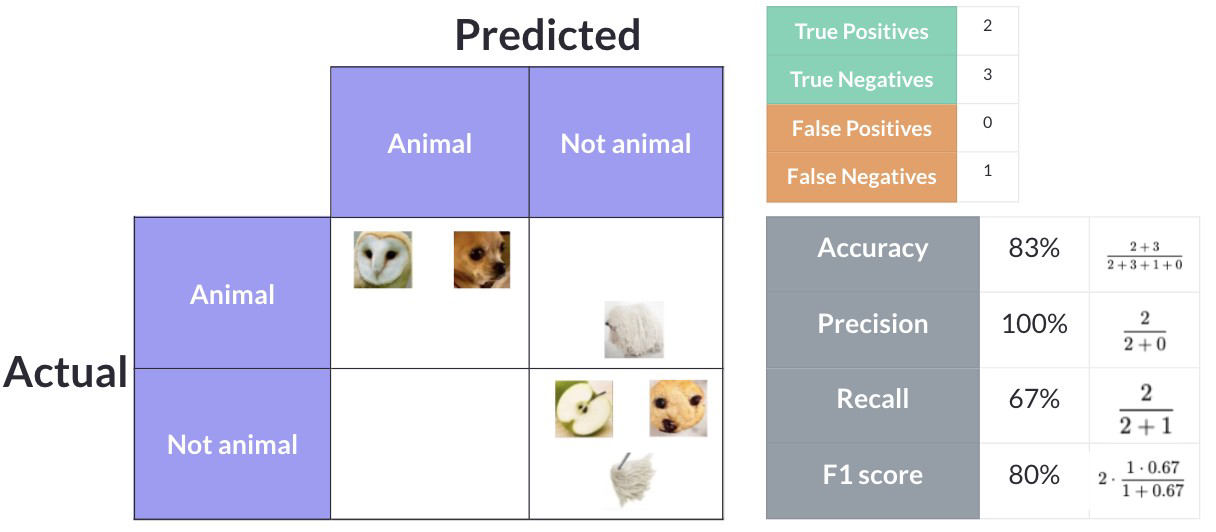
Fonte: Adaptado de [5].
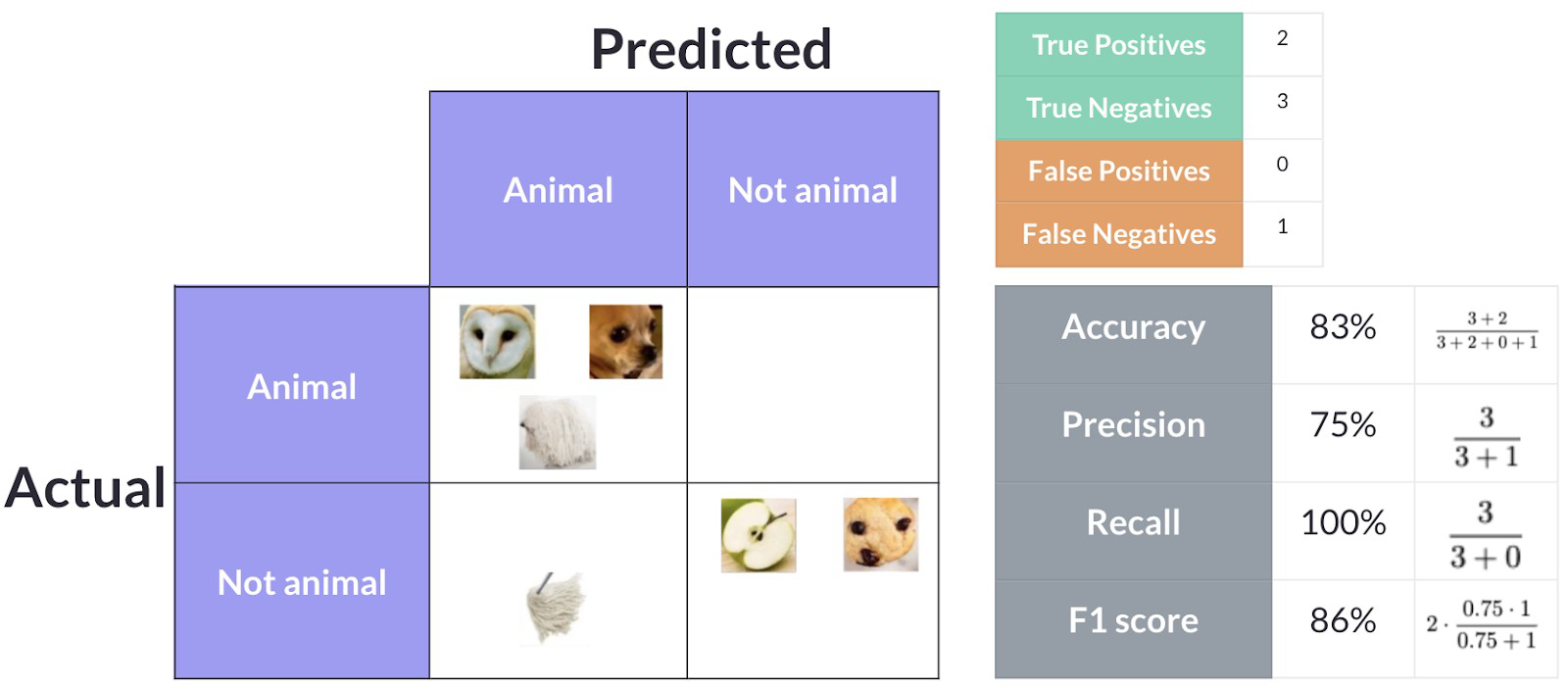
Fonte: Adaptado de [5].
5. CONCLUSÃO
Em resumo:
a) Sensibilidade refere-se a quanto bom todos os eventos positivos atuais estão em previstos eventos positivos.
b) Precisão refere-se quanto todos os eventos positivamente previstos foram corretamente previstos.
c) Acurácia é o quão corretamente todos os eventos foram previstos.
d) Especificidade é o quão bom está a previsão de eventos negativos.
Como saber qual deles procurar?
Se o pesquisador está mais interessado em casos de Falso Positivo, deve optar pela Precisão. Se os casos Falsos Negativos são o que o pesquisador procura, então Recall é uma boa medida. A Acurácia é melhor se houver um cenário tendencioso. Se for imparcial — Precisão e Recall. O F1 Score ajuda se o pesquisador está incomodado com ambos os valores. É uma média harmônica, ou seja, uma média ponderada de Precisão e Recall.
A sensibilidade é uma métrica valiosa para avaliar a capacidade de um modelo de aprendizado de máquina de identificar corretamente casos positivos. Um alto valor de sensibilidade sugere uma forte capacidade de capturar instâncias positivas, enquanto um baixo valor de sensibilidade indica uma maior probabilidade de falta de casos positivos. A interpretação da sensibilidade resulta no contexto dos requisitos do aplicativo e em conjunto com outras métricas de desempenho ajuda a determinar a eficácia e a adequação do modelo.
A especificidade é uma métrica fundamental no aprendizado de máquina que mede a capacidade do modelo de identificar corretamente casos negativos. Ela desempenha um papel crucial na avaliação do desempenho do modelo e sua adequação a aplicações específicas, onde é essencial identificação precisa de instâncias negativas.
6. REFERÊNCIAS
[1] KAKANADAN, U. Regression and performance metrics — Accuracy, precision, RMSE and what not!, Medium, 2024. Disponível em: <https://medium.com/analytics-vidhya/regression-and-performance-metrics-accuracy-precision-rmse-and-what-not-223348cfcafe>. Acessado em Jul 31, 2024.
[2] DILMEGANI, C. How To Measure AI Performance, AI Multiple Research, 2025. Disponível em: <how-to-measure-ai-performance>. Acessado em Mai 05, 2025.
[3] WRIGHT, S. A.; SCHULTZ, A. E. The rising tide of artificial intelligence and business automation: Developing an ethical framework. Business Horizons, v. 61, n. 6, p. 823-832, 2018. DOI: 10.1016/j.bushor.2018.07.001.
[4] STITH, L. What is Sensitivity and Specificity in Machine Learning. Robots.Net, Nov 2023. Disponível em: <https://robots.net/fintech/what-is-sensitivity-and-specificity-in-machine-learning>. Acessado em Ago 01, 2024.
[5] TIGERSCHIOLD, T. What is Accuracy, Precision, Recall and F1 Score?, Labelf, 2022. Disponível em: <https://www.labelf.ai/blog/what-is-accuracy-precision-recall-and-f1-score>. Acessado em Nov 13, 2024.